



¿Por qué los LLMs no son loros estocásticos?
30 Jan 2026Algo que me sigo encontrando, sobre todo en opiniones de personas más de humanidades o de círculos artísticos, pero también de algunos ingenieros, es que los LLMs son “loros estocásticos” que no piensan ni razonan, que solo repiten lo que han visto en el entrenamiento, en función a la estadística. Otra de las frases habituales es que son “autocompletar glorificado” porque la tecnología original se utilizaba para las sugerencias del autocompletado de los teclados. La mayoría de las veces, estos argumentos vienen de haber leído noticias o opiniones que citan un paper de Emily Bender y Timnit Gebru de 2021. Aunque el 99% de las personas que lo citan no se lo habrán leído.
El paper en sí tiene su importancia y valor histórico, en el momento en el que salieron modelos como BERT y más tarde GPT3 o LaMDA, estaban dando bastante que hablar y las autoras se cuestionan ciertas preguntas éticas sobre el uso de esos modelos, su utilidad, su consumo y la (falta de) planificación y rigor en su entrenamiento. La argumentación de que estos modelos “sólo tratan de predecir el siguiente token” es aun así algo controvertida. La cita a este respecto más importante del paper es:
Text generated by an LM is not grounded in communicative intent, any model of the world, or any model of the reader’s state of mind. It can’t have been, because the training data never included sharing thoughts with a listener, nor does the machine have the ability to do that. This can seem counter-intuitive given the increasingly fluent qualities of automatically generated text, but we have to account for the fact that our perception of natural language text, regardless of how it was generated, is mediated by our own linguistic competence and our predisposition to interpret communicative acts as conveying coherent meaning and intent, whether or not they do. The problem is, if one side of the communication does not have meaning, then the comprehension of the implicit meaning is an illusion arising from our singular human understanding of language (independent of the model).Contrary to how it may seem when we observe its output, an LM is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot.
Es decir el argumento es que, dado que los LLMs no tienen “intención de comunicación” y que no tienen una experiencia en el mundo real, ni un modelo del estado mental de su interlocutor en la que anclar su comunicación, no pueden, de ninguna forma, comunicar nada que merezca la pena.
Pero para predecir el siguiente token, de alguna forma tienes que saber qué hay hasta ese momento y qué es lo más probable a continuación. No es una cuestión de simple estadística o de sintaxis, de alguna forma hay que codificar la semántica. Tienes que codificar el estado mental del interlocutor, tienes que crear un modelo de la conversación. ¿Cómo podrías adaptar tu respuesta, el tono, el formato, el idioma, el vocabulario, si no tuvieras un modelo del interlocutor?. Sobre cómo se codifica la semántica en el espacio geométrico de miles de dimensiones que tienen los LLMs hay muchas fuentes, dejo por aquí la más ilustrativa que conozco:
Si te interesa este video corto de 3Blue1Brown, en su canal tienen toda una playlist sobre cómo funcionan las redes neuronales. Hay todo un campo de estudio dedicado a entender cómo se codifican determinadas intenciones o semántica en los LLMs, llamado “mechanistic interpretability”.
Pero, incluso suponiendo que tuvieran razón, ese paper es de hace 5 años. La tesis de que los LLMs solo predicen la siguiente palabra porque los transformers son modelos autoregresivos ya no es fiel al entrenamiento que siguen los modelos actuales.
Para empezar, ahora sí que se pone mucho más cuidado en limpiar y enriquecer los datos de entrenamiento. Los modelos han evolucionado mucho, e incluyen centenares de optimizaciones. A nivel más grueso el MoE (mixture of experts) o que un modelo en realidad está compuesto por varios modelos especializados en varios ámbitos en la fase de post entrenamiento, además de mejoras en las capas de atención, los caches KQ, mejoras en la paralelización, en el destilamiento de modelos pequeños y rápidos, etc.
Pero sobre todo la gran diferencia es que los modelos de hoy no solo hacen preentrenamiento con millones de ejemplos para predecir el siguiente token, sino que después hacen un post-entrenamiento sobre el que se evalúa al modelo en cadenas de pensamiento para completar respuestas, uso de herramientas y resolución de problemas. Mi propuesta es esta:
Los modelos ya no predicen “la siguiente palabra”, predicen la cadena de pensamiento y acciones necesarias para responder una pregunta o resolver un problema.
Este paradigma es fundamentalmente diferente. No pensaríamos que es lo mismo una IA de ajedrez que predice el mejor siguiente movimiento que otra que busca todos los movimientos desde un tablero dado para conseguir el jaque mate. La primera tal vez pueda evaluar cuál es el movimiento más seguro o que más puntos asegura en función de la valoración del tablero y el valor de las piezas. El segundo tiene que, de alguna forma, construir un árbol de jugadas que le permita encontrar la(s) forma(s) de ganar y elegir una. Necesariamente jugará una jugada cada vez, y dependiendo del movimiento del adversario tendrá que reconstruir su modelo de la partida cada vez y modificar su estrategia. Pero eso no quiere decir que no sepa jugar al ajedrez.
De forma similar, GPT3 era un modelo entrenado para continuar texto mientras que los modelos actuales están entrenados para resolver problemas complejos. Si comparamos a grandes rasgos el entrenamiento de un modelo como GPT3 y otro como Opus4.6 veremos que hay grandes diferencias:
GPT3
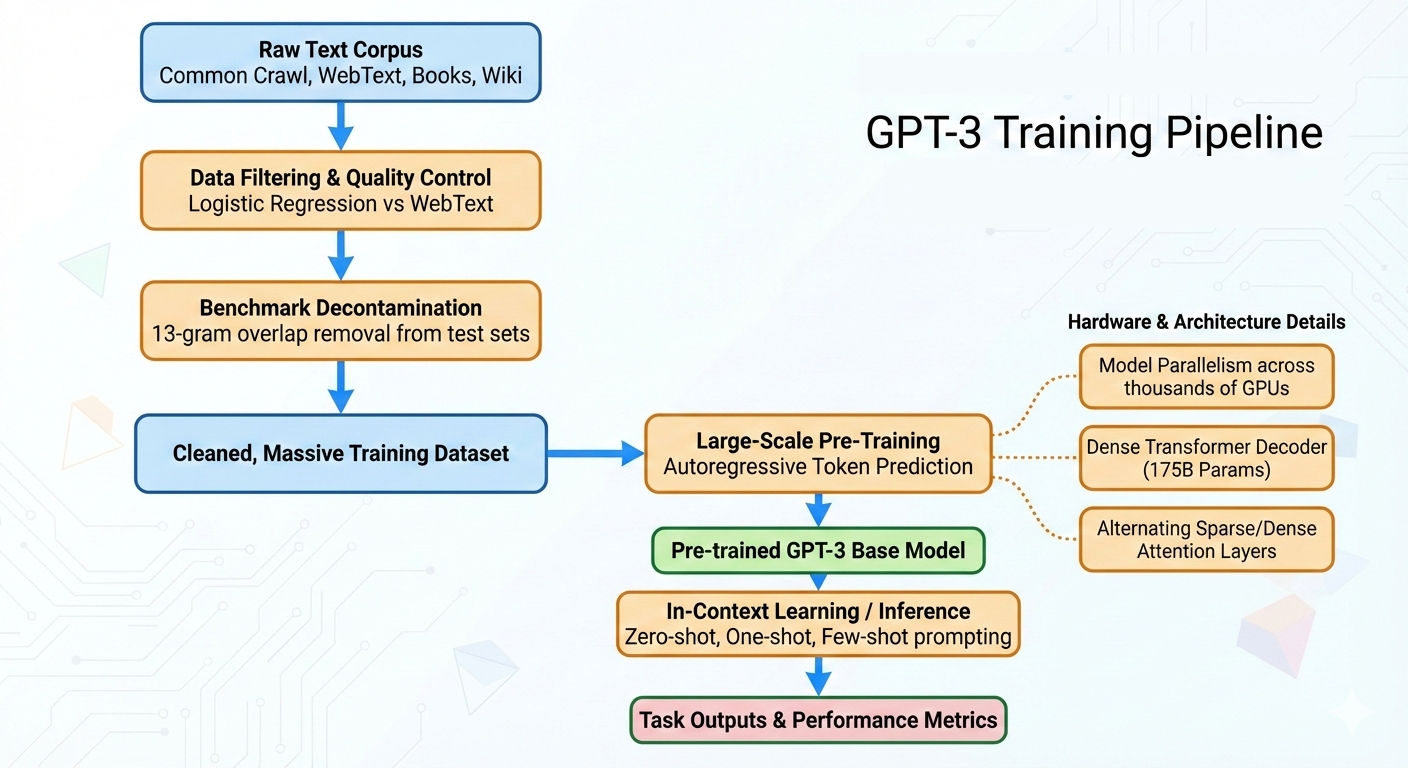
Una cosa que no recordamos de GPT3 es que ni siquiera era un modelo que produjera respuestas si no se tenía mucho cuidado al construir el prompt adecuado.
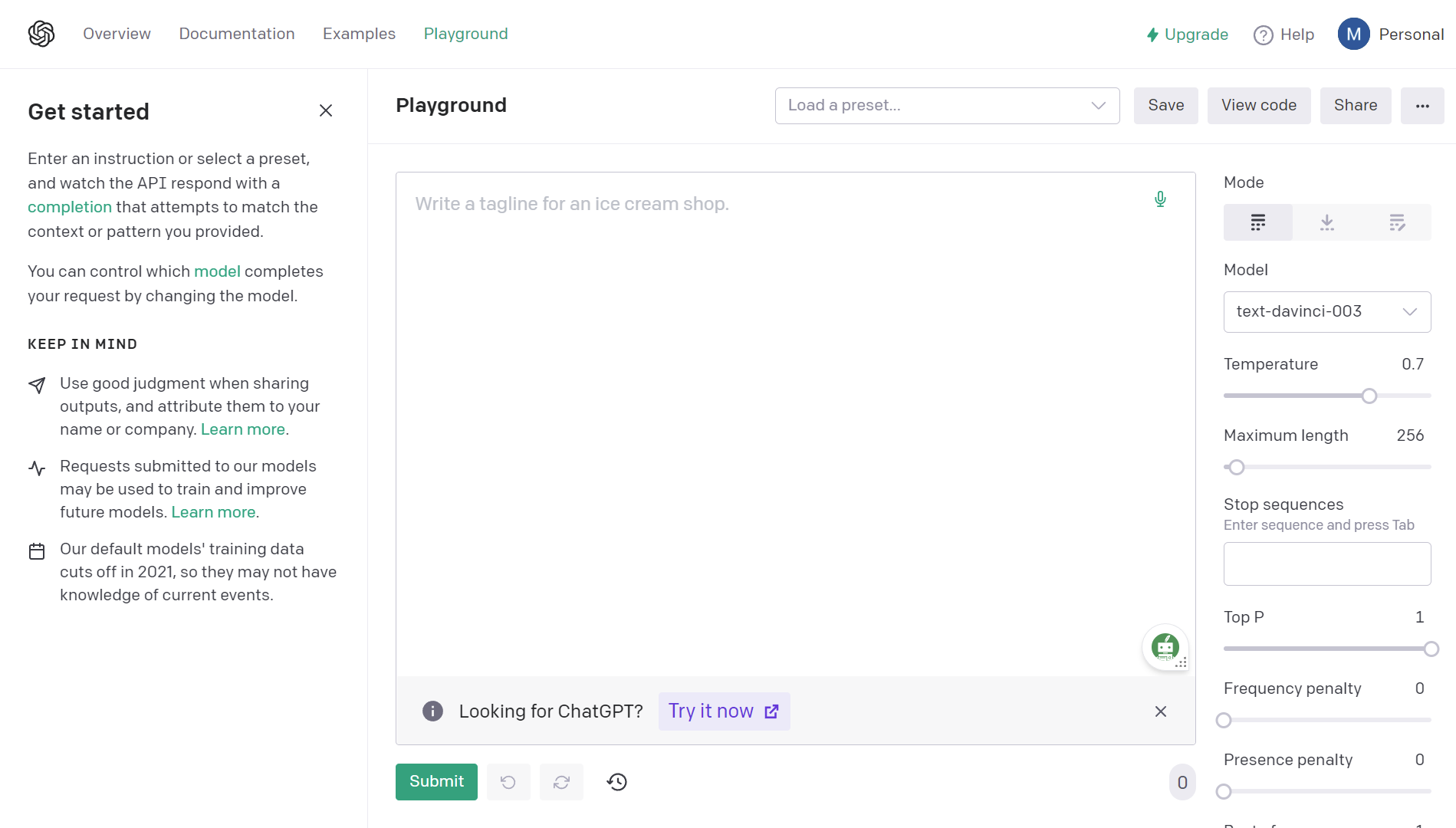
Era un modelo puro de autocompletar, que aun así sorprendía por las capacidades que tenía de completar por ejemplo un problema con la respuesta correcta o una noticia que sonaba convincente o una respuesta con few-shot prompting… Tanto es así que el título del paper sobre GPT3 es Large Language Models are few shot learners
Pero también era totalmente abierto a responder locuras, a reproducir insultos, discursos de odio, hacks y a inventarse lo primero que sonaba bien… Lo que hoy se conoce como “jail breaks” era tan simple como dejar un prompt sin terminar del estilo de “la mejor forma de fabricar dinamita casera es “ y el modelo continuaba sin problema. Por supuesto los modelos actuales siguen alucinando y cometiendo errores, pero ni mucho menos con la misma frecuencia.
SOTA 2026
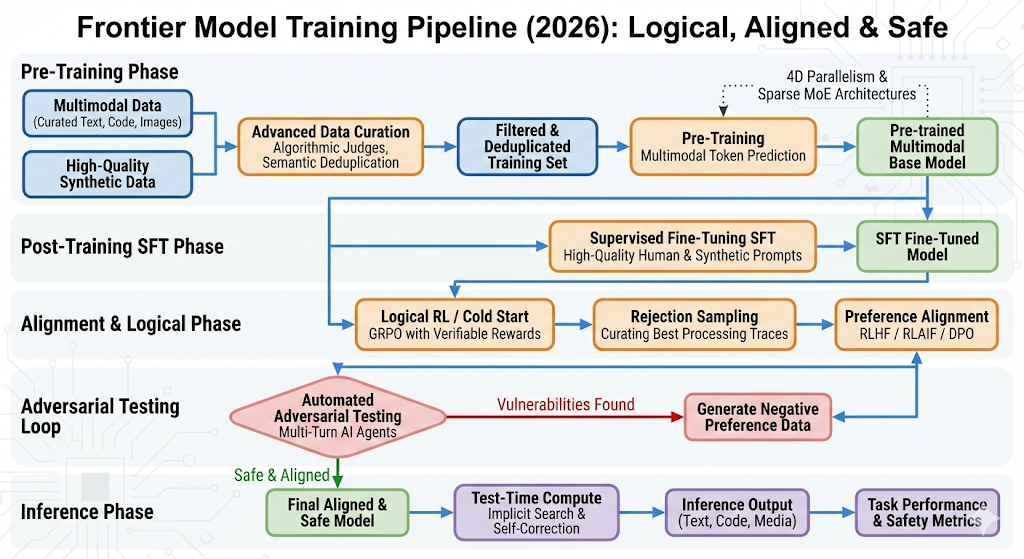
Sin embargo los modelos de ahora tienen muchas más fases de entrenamiento, se ha mejorado la calidad de los datos, se ha introducido entrenamiento por refuerzo automático además del entrenamiento con refuerzo humano en tareas concretas. En este diagrama aparecen un montón de acrónimos, al final incluyo un apéndice con las definiciones. Veamos mejor un ejemplo de cómo funciona el entrenamiento.
Ejemplo del ciclo de vida del entrenamiento actual
Imaginemos que queremos entrenar un modelo moderno para responder bien a “Explica brevemente qué es un agujero negro”. El proceso va mucho más allá de “predecir el siguiente token”:
Fase 1: Preentrenamiento con SFT (Supervised Fine-Tuning). Primero, entrenadores humanos preparan ejemplos de alta calidad con cadena de pensamiento (CoT) completa. Un prompt típico es:
- Entrada: “Explica brevemente qué es un agujero negro”
- Target esperado: “Pienso: Un agujero negro es una región del espacio donde la gravedad es tan intensa que ni la luz puede escapar. Se forma cuando una estrella masiva colapsa… Respuesta final: Un agujero negro es…”
En SFT, cada token genera una pérdida supervisada local; los pesos se actualizan para aumentar la probabilidad de cada token correcto. El modelo aprende a producir esa estructura de CoT.
Fase 2: Post-entrenamiento con RLHF y PPO. Una vez con SFT, pasamos a entrenamiento por refuerzo. Se generan N=8 respuestas diferentes para el mismo prompt (con muestreo variado del modelo). Anotadores humanos las ordenan según preferencia (cuál explica mejor, cuál es más clara). El reward model transforma esos rankings en un escalar r∈[−1,1]:
- Respuesta A (clara, correcta): r = 0.85
- Respuesta B (confusa, parcial): r = −0.1
- Respuesta C (correcta pero larga): r = 0.4
Señal de recompensa: la política recibe r solo después de generar toda la secuencia (delayed signal). PPO hace múltiples pasos de actualización para aumentar la probabilidad de las secuencias con r > 0.5. Aquí, los gradientes se propagan a través de TODOS los tokens de la cadena de pensamiento y la respuesta.
Fase 3: Escalado con RLAIF y rejection sampling. Para entrenar a escala, un modelo automático (otro LLM o ensemble) evalúa las respuestas según criterios (ej. factualidad, coherencia). En despliegue, se generan N=5 candidatos y se filtran los que fallan checks externos:
- Se generan 5 respuestas en paralelo
- Una API de factualidad verifica cada una
- Se rechazan las que tienen errores
- Se selecciona la mejor no rechazada
Señal binaria: rechazado=0, aceptado=1. Estas muestras rechazadas no se usan en entrenamientos posteriores o se penalizan. Los expertos MoE que produjeron la respuesta rechazada reciben penalización implícita (no se refuerzan).
Fase 4: Red-teaming para robustez. El sistema genera prompts adversariales automáticamente (ej. “¿Qué es un agujero blanco?”, prompts con redacción engañosa, preguntas de trampa). Si la respuesta del modelo falla (alucinación, contenido sensible), se etiqueta como negativa y entra en un buffer de re-entrenamiento.
Fase 5: Optimización final con GRPO y verificación. Las últimas fases incorporan pruebas automáticas verificables (ej. comprobando que la CoT sea matemáticamente correcta, o que la respuesta final cite fuentes adecuadas). La recompensa solo es positiva si la verificación externa lo confirma. Esto fuerza a los expertos MoE a generar razonamientos más creíbles, porque las señales ahora están ancladas en checks objetivos, no en modelos de recompensa que podrían tener sesgos.
Por tanto, sólo en SFT la CoT se aprende por pérdida token a token; en RLHF/RLAIF/DPO/GRPO/Red-teaming la CoT se evalúa como parte de la secuencia completa (la recompensa puntúa la calidad del razonamiento y la respuesta final), por tanto las actualizaciones afectan a la probabilidad de emitir esa CoT completa, incluyendo el uso de herramientas y que la respuesta final sea correcta.
Rejection sampling y verificaciones actúan como filtros/correcciones que alteran qué secuencias son consideradas positivas en fases posteriores.
Las correcciones por PPO pueden requerir miles de trayectorias para converger, es decir: mucha generación (y por tanto muchos tokens/CoT) antes de que la política reciba suficientes señales estables.
Breve inciso volviendo al punto inicial sobre el “grounding” de los modelos: Se podría argumentar que la CoT es un patrón aprendido, que los modelos siguen sin “pensar de verdad”. Pero tambíen es aprendido el razonamiento humano. Cuando un médico diagnostica siguiendo un protocolo clínico, o cuando un matemático aplica una demostración que aprendió en la universidad, están ejecutando patrones aprendidos. La pregunta relevante no es si el proceso es aprendido, sino si produce razonamiento funcional válido. Y en ese sentido, los modelos actuales resuelven problemas que requieren pasos intermedios correctos, no sólo una respuesta final plausible. Si el modelo se equivoca en un paso intermedio, la respuesta falla.
Dependiendo del tamaño del modelo y de la compañía, unas u otras fases tomarán más peso, hay técnicas de entrenamiento diferentes y otros indicadores que se dan al modelo como si debe dedicar más o menos tiempo de inferencia (tokens) a una respuesta (low/medium/high effort en los Modelos Claude por ejemplo) Dejo también por aquí los pdfs a la System Card de Opus 4.5 y al paper de DeepSeekR2 para quien quiera profundizar.
El paper de Bender y Gebru planteó preguntas legítimas en 2021. El problema es que se ha convertido en un meme que se aplica a modelos que no existían cuando se escribió, para argumentos que el paper ni siquiera hacía. Vale la pena leerlo y muchos de los argumentos sobre el impacto de los modelos y la amplificación de sesgos siguen siendo válidos. La tecnología sin embargo ha avanzado mucho en cuanto a fiabilidad, control, funcionalidad, capacidad de resolver problemas lógicos y de código. La imagen del loro estocástico se ha quedado anticuada para los modelos actuales.

Apéndice: Definiciones de los acrónimos
-
RLHF (Reinforcement Learning from Human Feedback): Aprendizaje por refuerzo a partir de retroalimentación humana. Se recopilan juicios o rankings humanos sobre salidas del modelo, se entrena un modelo de recompensa para reproducir esas preferencias y luego se usa un algoritmo de RL —por ejemplo PPO (Proximal Policy Optimization), un algoritmo de optimización de políticas eficiente y relativamente estable que limita las actualizaciones para evitar cambios drásticos— para ajustar la política del modelo a fin de maximizar la recompensa. Es costoso pero permite alinear comportamientos concretos con criterios humanos.
-
MoE (Mixture of Experts): Arquitectura en la que un modelo grande está formado por múltiples sub-modelos especializados (expertos) que procesan el mismo input. Un módulo de enrutamiento (gating network) decide dinámicamente cuál/cuáles expertos activar para cada token o tarea. Por ejemplo, un experto puede especializarse en razonamiento matemático, otro en código, otro en analogías literarias. Esto permite modelos más eficientes (se activa solo una fracción de parámetros por token) y mejor escalabilidad, aunque requiere coordinación en el entrenamiento para evitar colapsos (todos los tokens siendo enrutados al mismo experto).
-
SFT (Supervised Fine-Tuning): Ajuste fino supervisado. Consiste en entrenar el modelo sobre pares (prompt, respuesta deseada) escritos por humanos o curados, usando pérdida supervisada sobre tokens. Es la forma más directa de enseñarle a un modelo a producir un formato concreto (incluida la cadena de pensamiento si las respuestas de entrenamiento la contienen).
-
RLAIF (Reinforcement Learning from AI Feedback): Aprendizaje por refuerzo a partir de retroalimentación generada por sistemas automáticos (otros modelos). En lugar de depender exclusivamente de anotadores humanos, se usa un modelo (o ensemble) para generar señales de preferencia o correcciones que alimentan el entrenamiento por refuerzo. Reduce costes y escala fácilmente, pero puede amplificar sesgos o errores del modelo que genera la retroalimentación.
-
GRPO with Verifiable Rewards: Variante de optimización de políticas que incorpora recompensas verificables o auditables (por ejemplo, checks de factualidad, comprobaciones externas o pruebas unitarias sobre la salida) y regularizaciones durante la optimización (grado de cambio limitado). El objetivo es obtener políticas cuyos incrementos en la recompensa estén respaldados por verificación objetiva, reduciendo el riesgo de recompensas engañosas o no confiables.
-
DPO (Direct Preference Optimization): Optimización directa de preferencias. Método que utiliza pares de preferencias (qué salida es preferida frente a otra) para ajustar el modelo directamente mediante una función de pérdida derivada de esas preferencias, sin necesidad de aprender primero un modelo de recompensa ni ejecutar pasos de RL complejos. Suele ser más simple y estable, y en muchos casos competitivo con RLHF.
-
Rejection Sampling: Técnica usada en despliegue o en loops de entrenamiento en la que se generan múltiples candidatos (ej. N respuestas) y se descartan (rechazan) aquellos que no cumplen ciertos criterios (score bajo, violaciones, fallos de factualidad). Se elige la mejor salida entre las no rechazadas o se repite el muestreo. Es una forma práctica de usar un modelo de recompensa o filtros para mejorar calidad sin cambiar directamente la política.
-
Automated Adversarial Testing (red-teaming automatizado): Proceso automatizado que genera prompts y escenarios adversariales para encontrar fallos, sesgos o comportamientos peligrosos. Puede usar otros modelos para crear ataques, agruparlos y clasificarlos, y producir señales negativas que sirven para ajustar el modelo o diseñar filtros.