



Reseña Out of the Tarpit
07 Jan 2018Conforme leo algunos papers quiero ir subiéndo los más interesantes al blog y comentándolos, aunque sea de pasada, para ayudarme a recordarlos y tenerlos a mano para volver a ellos cuando quiera. La idea no es mía, la he tomado de sitios como the morning paper o el directorio de Bret Victor
Out of the tarpit - Mosley and Marks 2006
Siempre me gustan este tipo de ensayos que hablan de el trabajo del programador, y cómo todos coinciden en que hay que tratar de conseguir la mayor simplicidad posible, siendo el escenario ideal la programación declarativa. Este paper en concreto, además, se centra en uno de los temas favoritos de los desarrolladores: como crear un framework de trabajo ideal, que permita ese estilo simple y declarativo de desarrollo. Ha tenido bastante repercusión en la industria y lo he visto citado más de una vez por conocidos desarrolladores. Hago un resumen de las ideas claves, aunque nada como leer el paper tranquilamente para que cale bien.
¿Qué es la simplicidad?
La simplicidad para el desarrollador es siempre como un espejismo. Como una ilusión optica que sabes que no puede ser verdad. Para los ojos de los no desarrolladores todo debería ser tan fácil como especificar en unas cuantas frases o gráficos el problema y el ordenador debería poder hacer el resto. Para eso los tenemos, para hacer todo cálculo que no sea puramente creativo.
O eso parece. Cuando te acercas a los detalles, cuando te pones a programar, te das cuenta de que necesitas ser mucho más concreto y todos esos pequeños detalles que se obviaron en la descripción inicial son imprescindibles para tener un sistema que funcione y son el 80% del trabajo.
Por ejemplo, un cliente normal solo piensa en “guarda estos datos en la base de datos” Pero nosotros tenemos que decidir si en una base de datos relacional o de documentos por ejemplo (¿Postgress o MySQL? ¿Mongo, MariaDB, Couch, Dynamo? ¿Redis, Memcache? …), cómo normalizar los datos para almacenarlos, qué índices deberemos crear para facilitar las búsquedas, qué tipos de datos tienen los diferentes campos que se quieren guardar, que tamaño total tienen los datos y si se podrán mantener en RAM, se deben cachear o no, cómo se va a acceder a esos datos posteriormente y si deben replicarse a lo largo y ancho del mundo, si queremos que el almancenamiento sea immutable tipo log o mutable, qué permisos y qué privacidad tienen los datos, ¿quién debe poder acceder a ellos? ¿Quien no debería poder? ¿Hay leyes que protejan estos datos? ¿Pueden ser un atractivos para un atacante? etc, etc, etc…
Algunas de esas preguntas debe de responderlas el cliente o el proyecto, si no fueron respondidas en las especificaciones, deberíamos preguntar directamente para saber qué hacer. Pero otras dependen únicamente del hecho de que estamos representando los datos en ordenadores que tienen limitaciones físicas y temporales. Esto último es lo que en Out of the tarpit llaman complejidad accidental. Es decir, el desarrollador debería poder escapar de toda esa complejidad derivada de estar representando los datos como 1’s y 0’s centro de un disco magnético o de una matriz de transistores. Deberíamos poder ignorar los detalles sobre velocidad de acceso, espacio, tipos de datos (a nivel de bytes) y demás limitaciones del hardware para centrarnos en el problema en sí.
¿Cómo lo conseguimos?
La propuesta de los autores es la Programación Funcional Relacional (FRP en el original) que es un término que han inventado ellos para el framework que proponen. Pero antes de llegar a la propuesta final, dejan claro que es una cuestión de disciplina y de limitar la expresividad del/los lenguajes de programación para buscar la simplicidad.
Para darle autoridad a esta afirmación, a la necesidad de huir de la complejidad, los autores citan a grandes personalidades del desarrollo como Hoare, Backus, Corbato, Brooks y Dijsktra. En la actualidad, una de las principales personalidades del mundo del desarrollo que es conocido por seguir este mismo discurso es Rich Hickey, el creador de Clojure, y en especial su charla “Simple made easy”
El de la simplicidad es un mantra repetido a lo largo y ancho del mundo del desarrollo, KISS, YAGNI, POJO son algunos acrónimos que se vienen a la mente. Pero cómo conseguirla no es tan sencillo y en este documento Mosley y Marks intentan dar una respuesta mediante una arquitectura que huya de la complejidad y del acoplamiento.
El paper identifica dos fuentes principales de complejidad que enturbia el código: estado y lógica de control. En un mundo ideal la lógica de control sería totalmente prescindible y el único estado necesario sería la entrada del usuario, todo lo demás debería poderse derivar mediante reglas declarativas hasta obtener un resultado, de forma parecida a una demostración matemática. De hecho una de las referencias y de las herramientas del framework propuesto es la programación lógica, en la que el programador declara una serie de reglas o hechos que el compilador tomará como verdades absolutas o axiomas que podrá usar para derivar el resultado del programa junto con la entrada del usuario.
Aun así, cualquier problema no trivial tendrá cierta dificultad, esta es la complejidad esencial: aquella innerente al problema que estamos tratanto, suponiendo que los cálculos se hacen de forma ideal y no limitados por el hardware y los problemas del mundo real.
Pero no vivimos en un mundo ideal, los ordenadores son reales y no imaginarios y si queremos ejecutar algo en ellos tenemos que atenernos al marco que tenemos. Las dificultades que surgen de representar el problema en el ordenador y poder interactuar con él es lo que los autores llaman complejidad accidental.
Para atomizar y atacar esta complejidad se basan en dos principios: evitar la complejidad y separarla cuando no puedes evitarla.
Evitarla quiere decir no crear ningún estado o lógica que no sea absolutamente necesaria para resolver el problema, todo estado que se pueda derivar de la entrada, deberá derivarse y no almacenarse a no ser que sea realmente necesario para comprender mejor el problema.
Separarla quiere decir que, si vemos que necesitamos ese estado o esa lógica de control, debemos separarlo a donde pertenece dentro de la arquitectura.
Esto así dicho suena más fácil de lo que es, ya que al final la responsabilidad recae en la diligencia del programador. Para ayudar en esta labor se establece que la arquitectura debe de seguir este diagrama:
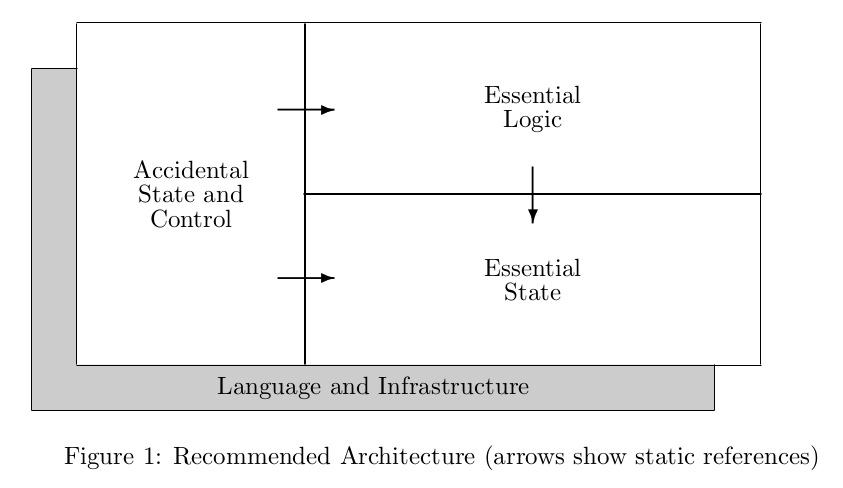
Para mi este es un diagrama más importante que el posterior de FRP porque es más genérico: tenemos un lenguage y una infraestructura que nos van a permitir expresar el estado esencial en base a una serie de axiomas independientes del resto del programa, es decir que los cambios en el resto del programa nunca deben suponer cambios en el estado esencial. Si el estado esencial cambia, seguramente se vean afectados los otros componentes, pero este núcleo no debe verse afectados por cambios en el exterior.
De forma parecida, la lógica esencial solo puede verse afectada por cambios en el estado esencial, pero no por cambios en el el control y estado accidental o en la infraestructura y la logica y el estado accidentales son dependientes tanto de la lógica esencial como del estado esencial y sirven para conectarlos al mundo real.
FRP es una de las muchas posibles implementaciones de esta idea. Usando el modelo relacional para definir el estado esencial y la programación funcional para la lógica se pretende crear esta separación de responsabilidades y así mantener un sistema simple y fácil de modificar.
De ahí que la propuesta sea también usar varios lenguajes, muy restringidos, para cada parte del framework, para evitar que los programadores caigan en la tentación de “acortar camino” mezclando lógica con estado. Un poco como CSS y HTML que son lenguajes muy restringidos y con una función concreta, salvo que en el caso del desarrollo web el control y el estado los gestionamos con JavaScript que es un lenguaje dinámico y muy laxo.
En este sentido me llama la atención que la propuesta sea tener lenguajes restringidos cuando la tendencia en todos los lenguajes es incorporar más y más funcionalidad.
Personalmente creo que el objetivo de tener un programa totalmente declarativo y funcional ayudaría mucho al desarrollo, pero no es la tendencia que veo en los lenguajes actuales o futuros. Lo que yo veo, extrapolando a partir del panorama actual, es lenguajes cada vez más ricos e intercambiables, cada vez más expresivos y que se pueden usar en cualquier situación. Ahora mismo hay una explosión de compiladores y traductores. Compilar Haskell o Clojure o Reason a JavaScript, C o C++ a wasm, compilar javascript a binario, Clojure sobre Java o sobre .NET, Crystal es como un Ruby que compila y es super rápido…
La idea es que no importa en el lenguaje que trabajes, pronto podrás hacer cualquier tipo de aplicación, para la web o fuera de ella, con cualquier lenguaje. Veo los lenguajes de programación del futuro un poco como los lenguajes naturales: cada uno tendrá su lenguaje “nativo” o preferido y con él podrá hacer lo mismo que con cualquier otro. Por supuesto habrá bilingües y políglotas, y algunos lenguajes seguirán siendo mejor para algunas cosas y habrá dominios que estén completamente en un lenguaje, pero eso también pasa con los lenguajes humanos y esa es la tendencia que veo. Al final la complejidad del mundo real no se puede encasillar o domar y nosotros no somos máquinas. Pensar con restricciones no es nuestra forma natural de expresarnos y siempre tendemos a la solución que nos dé más libertad de expresión, esa es una de las razones del éxito de JavaScript o de que diferentes dialectos de LISP sigan usándose.
Sin embargo sí que podemos ver una tendencia hacia una programación más funcional y más en la línea de lo que marca este paper. De hecho el paper tuvo una gran influencia en David Nolan, creador de Om, que a su vez influyó en Redux y hoy en día tenemos muchas aplicaciones web que tienen una única fuente de verdad, un store con el estado de la aplicación, de forma similar al “estado esencial” del que hablábamos.
Además, este estado sólo se puede modificar mediante el store para controlar que la lógica que modifica ese estado esté centralizada en los Reducers, de forma parecida al motor de lógica esencial del que habla el paper. Lo que nos falta es una infraestructura que cumpla las promesas del paper y es que, aunque React, Vue o Angular hagan la interacción con el DOM declarativa y nos permitan separar también la capa de presentación, la interacción del usuario todavía embarra mucho el código.
Los Observables de RxJs mejoran también mucho esta experiencia y la hacen más funcional y fácil de componer, pero aun no tenemos una infraestructura que aúne todos estos elementos de forma simple y transparente al programador. Al contrario la complejidad accidental de tener que combinar un lenguaje con variables no inmutables y las distintas librerías más el hecho de que todo esto debe transpilarse y empaquetarse para poder servirlo en la web hace que sea necesaria mucha disciplina para mantener esa complejidad accidental fuera del resto del sistema.
Otros intentos de mejorar el desarrollo de aplicaciones y conseguir una buena separación de responsabilidades son Elm y ClojureScrip. Ambos lenguajes, aunque muy diferentes, pretenden esa simplidad gracias a la programación funcional y a la inmutabilidad de los datos y están, en mi opinión, un paso más cerca del objetivo. Veremos como evoluciona todo esto, pero ciertamente da la sensación de que estuviéramos en otro de esos grandes momentos de creación de nuevas ideas y lenguages, como ocurrió en los 50 y más tarde en los 80, pero con una masa crítica de desarrolladores mucho mayor, lo que a la vez permite tener mucha más creatividad pero también que se de el fenómeno que comentaba antes de lenguajes sobredimensionados y programadores monolingües que no necesitan salir de su lenguaje o su estilo de programación para continuar desarrollando.
Este me parece un ensayo importante para repasar muchos de los nuevos lenguajes y frameworks que hemos visto surgir en los últimos años. El desarrollo sigue evolucionando y tratando de alcanzar esa meta última de la simplicidad y el lenguaje declarativo ideal. Pero por el camino miles de programadores hacen su trabajo cada día ajenos a todas estas reglas y reflexiones, en lenguajes cada vez más potentes y polivalentes que les permiten no plantearse si realmente lo están haciendo bien. Para mi esta dicotomía siempre ha existido y siempre existirá, no es lo mismo programar por afición que profesionalmente, no es lo mismo desarrollar un producto que una solución SaaS. Cada proyecto tiene un lenguaje que se adapta mejor al problema y cada programador tiene un lenguaje favorito o que conoce mejor.
No sé que vendrá en el futuro, pero lo que puedo tener seguro es que no será una única solución que lo resuelva todo y haga que todos trabajemos al unísono en una especie de paraíso de la programación donde resolvemos todos los problemas de forma declarativa. Out of the tarpit da muchas claves para mantener a raya la complejidad y el acoplamiento, que es algo que todos los programadores profesionales debemos tener en cuenta, pero queda un largo camino hasta que ideas así sean habituales en este magma informe que es el desarrollo de software.